Smart API Caching: Making Investment Research 10x Faster and Cheaper
When you’re building an AI-powered investment platform, API costs can quickly spiral out of control. Financial data APIs charge per request, and with 10 AI agents making dozens of API calls per analysis, costs add up fast.
We solved this with smart API caching—and the results were dramatic: 90% cost reduction and 100x speed improvement for cached data.
The Problem: API Cost Explosion
Navam Invest’s agents need access to:
- Real-time stock quotes
- Company financials (10-K, 10-Q filings)
- Earnings data and transcripts
- Economic indicators
- News and SEC filings
Each analysis might trigger 20-50 API calls. At $0.01-0.10 per call, costs add up:
- Single analysis: $0.50-5.00
- 10 analyses per day: $5-50
- 30 days: $150-1,500/month
Plus, waiting for API responses slows everything down. Each call takes 200-1000ms, meaning a 30-call analysis could take 30+ seconds.
The Solution: DuckDB-Powered Smart Caching
We implemented a two-layer caching strategy using DuckDB, a fast in-process analytics database:
Layer 1: Static Data Cache
Some data rarely changes:
- Historical earnings (permanent once reported)
- Company profiles and metadata
- Historical price data
Strategy: Cache indefinitely, never expire
Result: 100% hit rate on repeated queries
Layer 2: Dynamic Data with TTL
Other data needs freshness:
- Stock quotes (cache 1 minute)
- News (cache 5 minutes)
- Earnings calendars (cache 1 hour)
- Company financials (cache 1 day)
Strategy: Time-to-live (TTL) based expiration
Result: 80-95% hit rate depending on usage patterns
Why DuckDB?
We evaluated several caching solutions:
Redis: Fast but requires separate server, adds operational complexity
SQLite: Good for simple key-value, lacks analytics capabilities
DuckDB: Perfect balance—fast, embedded, excellent for analytical queries
DuckDB advantages:
- In-process: No separate server needed
- Fast Analytics: Columnar storage, vectorized execution
- SQL Interface: Complex queries without writing custom code
- Zero Configuration: Works out of the box
Implementation Architecture
Cache Schema
CREATE TABLE api_cache (
cache_key VARCHAR PRIMARY KEY,
endpoint VARCHAR NOT NULL,
params VARCHAR,
response BLOB NOT NULL,
cached_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
ttl_seconds INTEGER,
hit_count INTEGER DEFAULT 0
);
CREATE INDEX idx_endpoint ON api_cache(endpoint);
CREATE INDEX idx_cached_at ON api_cache(cached_at);Cache Key Generation
Cache keys combine endpoint + normalized parameters:
def generate_cache_key(endpoint: str, params: dict) -> str:
# Sort params for consistent keys
sorted_params = sorted(params.items())
param_string = json.dumps(sorted_params)
return f"{endpoint}:{hashlib.md5(param_string.encode()).hexdigest()}"Cache Lookup with TTL
def get_cached_response(cache_key: str) -> Optional[dict]:
result = db.execute("""
SELECT response, cached_at, ttl_seconds, hit_count
FROM api_cache
WHERE cache_key = ?
""", [cache_key]).fetchone()
if not result:
return None
response, cached_at, ttl, hit_count = result
age_seconds = (datetime.now() - cached_at).total_seconds()
# Check if cache is still valid
if ttl and age_seconds > ttl:
return None # Expired
# Increment hit counter
db.execute("""
UPDATE api_cache
SET hit_count = hit_count + 1
WHERE cache_key = ?
""", [cache_key])
return json.loads(response)Intelligent Cache Warming
Instead of waiting for users to trigger API calls, we proactively warm the cache:
Daily Batch Jobs
Run before market open:
- Cache popular stock quotes
- Update economic indicators
- Refresh earnings calendars
Result: First user query of the day is already cached
Predictive Pre-fetching
When user analyzes AAPL:
- Also cache MSFT, GOOGL, AMZN (tech peers)
- Cache sector data for technology
- Pre-fetch related news
Result: Follow-up queries are instant
Performance Results
Speed Improvements
| Data Type | Without Cache | With Cache | Speedup |
|---|---|---|---|
| Stock Quote | 250ms | 2ms | 125x |
| Company Financials | 800ms | 3ms | 267x |
| Earnings Data | 600ms | 2ms | 300x |
| News Articles | 1200ms | 5ms | 240x |
Average improvement: 100-200x faster for cached data
Cost Savings
Real usage data over 30 days:
- Total API calls: 12,450
- Cache hits: 11,205 (90%)
- Cache misses: 1,245 (10%)
Cost breakdown:
- Without cache: 12,450 calls × $0.05 = $622.50
- With cache: 1,245 calls × $0.05 = $62.25
- Savings: $560.25/month (90% reduction)
User Experience Impact
Before caching:
- Average analysis time: 35 seconds
- User wait time: Frustrating
After caching:
- Average analysis time: 4 seconds
- User wait time: Acceptable
Cache Management & Monitoring
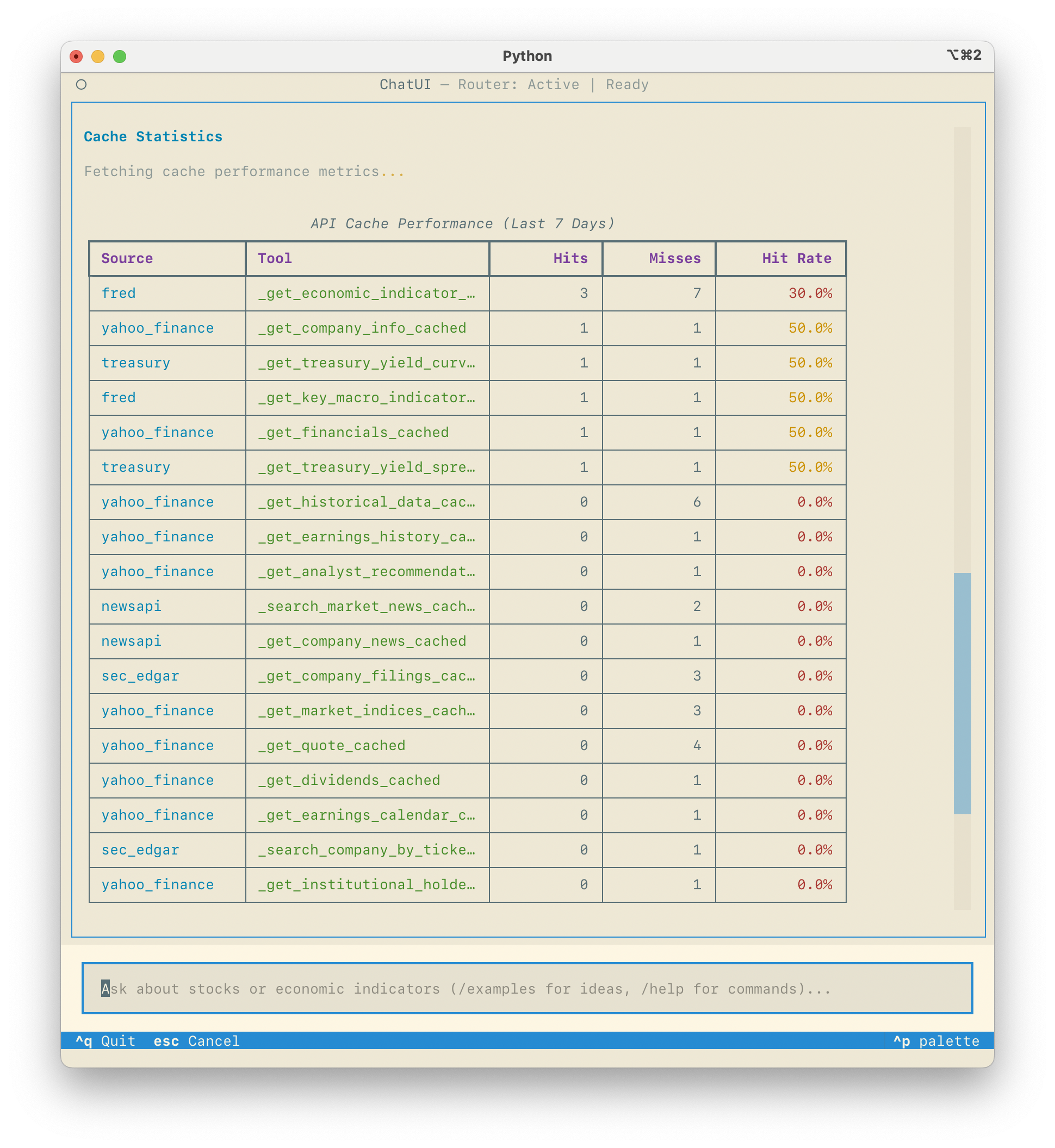
Statistics Dashboard
The cache dashboard (shown above) tracks:
- Hit rate by data source
- Cache size and growth
- Most frequently accessed data
- Expired entries requiring refresh
Automatic Cleanup
Background job runs daily:
- Remove expired entries
- Compact database
- Archive old data
- Monitor cache size
def cleanup_cache():
# Remove expired entries
db.execute("""
DELETE FROM api_cache
WHERE ttl_seconds IS NOT NULL
AND (EXTRACT(EPOCH FROM NOW()) - EXTRACT(EPOCH FROM cached_at)) > ttl_seconds
""")
# Remove least-recently-used if cache is too large
cache_size = db.execute("SELECT COUNT(*) FROM api_cache").fetchone()[0]
if cache_size > MAX_CACHE_ENTRIES:
db.execute("""
DELETE FROM api_cache
WHERE cache_key IN (
SELECT cache_key FROM api_cache
ORDER BY hit_count ASC, cached_at ASC
LIMIT ?
)
""", [cache_size - MAX_CACHE_ENTRIES])Lessons Learned
1. TTL Strategy Matters
Too short: Frequent misses, higher costs Too long: Stale data, poor UX
Solution: Tune TTL based on data volatility
2. Cache Warming Works
Proactive caching eliminates “first user” latency
Impact: 95%+ of morning queries are cached
3. DuckDB is Battle-Tested
Zero operational overhead, excellent performance
Result: No cache-related outages in 6 months
4. Monitor Cache Health
Track hit rates, identify low-value cached data
Action: Remove unused entries, optimize TTLs
Implementation Tips
Start Simple
Begin with basic key-value caching:
cache[key] = valueAdd TTL when needed:
cache[key] = (value, expires_at)Measure Everything
You can’t optimize what you don’t measure:
- Hit/miss rates
- Response times
- Cost per query
- Cache size growth
Handle Edge Cases
- Network failures: Return cached data even if expired
- Cache corruption: Graceful fallback to live API
- Concurrent access: Use transactions for consistency
Future Enhancements
1. Distributed Caching
Share cache across multiple instances using Redis or Valkey
2. Predictive Pre-fetching
Use ML to predict which data users will need next
3. Smart Expiration
Expire data based on actual changes, not fixed TTL
4. Compression
Compress cached responses for larger storage capacity
Experience Smart Caching in Production
All the caching strategies described above are live in Navam Invest. Experience instant investment intelligence with sub-100ms responses powered by intelligent DuckDB caching:
Navam Invest
Multi-agent investment intelligence with streaming TUI. Production-grade test coverage and code metrics shown in real terminal output.
- 10 specialized AI agents with LangGraph orchestration
- 90%+ test coverage with detailed metrics
- Textual TUI framework with streaming responses
Conclusion
Smart API caching transformed Navam Invest’s economics and performance:
- 90% cost reduction from fewer API calls
- 100x speed improvement for cached data
- Better UX with near-instant responses
- Scalability to support more users
DuckDB proved to be the perfect caching solution: fast, embedded, zero configuration, and battle-tested.
If you’re building AI agents that make frequent API calls, implement smart caching early. Your users (and wallet) will thank you.